Recently, the temperature in the Arctic appears to have hit a new continental high, close to 70 degrees.
That’s leading to continued melting of glaciers in the Arctic and around the world. But how will that impact the world’s ecosystems?
Dr. David Hik is an Associate Dean of the Faculty of Science as well as a Professor of Biological Sciences at Simon Fraser University. For more than 30 years, Dr. Hik has been studying mountain regions and has seen firsthand the impact climate change has had.
A recent study he did found that 80 percent of the glaciers in Alberta and British Columbia could melt in the next 50 years.
Below, listen to the conversation or read the transcript, and hear Dr. David Hik’s thoughts on:
- Effects of glaciers melting on the environment and humans
- How fast glaciers are melting
- Why glaciers are important
- What cities and countries will be most vulnerable to sea-level rise
- How to prevent glaciers from melting
- How does climate change affect plants and animals
- How do animals adapt to climate change
- What happens to animals that cannot adapt to the changes in their environment
- What is biodiversity and why it’s important
Want to hear more from Dr. David Hik?
Enroll for free in
Or if you’re a member of the press, or .
___________________________________________________________________________
Transcript
Coursera [00:00:00]: From Coursera, this is Emma Fitzpatrick, and today, I’m talking to Dr. David Hik of Simon Fraser University in Canada. There, he’s an Associate Dean of the Faculty of Science as well as a Professor of Biological Sciences.
For more than 30 years, Dr. Hik has been studying plant and animal populations and how they interact with each other as well as their environment.
Much of his work has been in mountain regions, specifically the Yukon. That’s a territory in Northwest Canada, near Alaska. It’s a wild mountain area that includes Canada’s largest mountain peak glaciers and glacier-fed lakes.
Through his research in that area, he’s seen firsthand the impact of climate change and has been studying the long-term effects of a warming planet.
A recent study he did found that 80 percent of the glaciers in Alberta and British Columbia could melt in the next 50 years.
Today, we’re talking with him in more detail about the impact climate change will have on our environment, how that will impact animal, plant, and human life, and the importance of biodiversity overall.
Let’s go ahead and get started.
I’d love to hear, from your perspective, how has the landscape in the Yukon, where you’ve done a lot of research over years and decades, changed from when you first visited it?
What kind of firsthand ways are you seeing climate change affect that area you know so well?
Dr. David Hik[00:01:24]: Well, the Yukon is a remarkable place. Many people know it, probably from the Klondike Gold Rush and the sort of colorful history of what happened at the end of the 1800s.
But, it is a landscape that I first visited in 1988. The Southwest Yukon is home to wild forests and big mountain peaks–the largest ice fields outside of the polar regions.
And I’ve been studying those environments for all of that time. But in many ways, the biggest changes are the things that you see happening right in front of you, year after year as you return.
So, for example, about 20 percent of the surface area of those glaciers has been lost in the last 50 years, and it’s highly visible. The glaciers are thinning by a meter a year. That means the surface is melting, and they’re getting thinner and smaller. And all of that water is flowing out through the rivers and the lakes and ultimately into the oceans.
Just four years ago, we had one of those big rivers that’s fed by the Kaskawulsh Glacier essentially divert from the Arctic Basin into the Pacific Basin. And so, lake levels dropped by two meters, and the color of the lake changed.
So, those are just some of the really dramatic examples that we’ve seen in the glaciers. But we see the same thing happening in the forest and in the Alpine–and if you look a little more closely to some of the plants and animals that are living in those environments as well.
Coursera [00:02:44]: And of course you’re a scientist, so you’ve got that eagle eye to really be noticing these things.
But if you were someone who lived in the area, these would all be changes that you couldn’t help but notice either.
Dr. David Hik [00:02:55]: That’s right. And so for the people who live in that part of the world–fairly small communities, far away from larger centers, out along the Alaska Highway. Many of them, the traditional homes of First Nation People in Northwestern Canada. They experience these changes firsthand.
So, for example, that decrease in the lake level: that affects how people are able to go fishing, or in winter, to travel across the ice safely to trap lines.
Another big disturbance in the 1990s and early part of the 2000s was a huge outbreak of spruce bark beetle. So, the forest there is predominantly white spruce, and the bark beetle killed about 350,000 hectors of the forest in that part the Yukon–and left all of these standing dead trees. And that leads to the potential for a greater forest fire risk.
Coursera [00:03:44]: Yeah, It’s hard to talk about some of these issues without talking about all of the ways that they’re interconnected with the different ecosystems around.
As you study glaciers melting, do you specifically look at that one issue? Or do you look at it as a domino effect? Because this is happening, X, Y, and Z are also going to happen?.
Dr. David Hik [00:04:04]: The thing that connects all of the changes we’re seeing, especially in mountains and in the Arctic, are related to changes in what we call the cryosphere.
So, the cryosphere is the frozen part of the natural environment. It’s snow, it’s ice, and it’s permafrost or frozen ground. When snow and ice and frozen ground either thaws or melts– when it undergoes a phase change from being a solid to a liquid–those effects are dramatic.
That’s what we’re seeing in the parts of the world that are changing most rapidly, and that fundamentally is a one-way street as the Earth gets warmer and is what precipitates all of these other changes in the system.
Coursera [00:04:46]: Yeah. And on that front, how fast exactly are glaciers, ice, snow–that cryosphere that you mentioned– how fast are they melting?
Dr. David Hik [00:04:55]: Well, globally, glaciers are melting quite rapidly. The big ice sheets in Greenland or in the Antarctic are a little more stable, but mountain glaciers around the world, the mid-latitude glaciers–say in Europe or North America or the Himalaya–they’ve been melting quite rapidly.
They probably can stabilize if the global temperature increases around 1.5 degrees, but at two degrees, we see these glaciers disappear almost entirely by the end of the century.
And that has huge impacts on water that feeds the largest rivers in the world. Half of humanity relies on water that flows out of mountains either from snow or glaciers, into the lowlands.
Since industrial times, atmospheric CO2 has increased from about 280 parts per million up to where it is right now, about 415 parts per million. And that’s led globally to an increase of 1.1 degrees.
And we see the projections are at the current rate that greenhouse gases are increasing in the atmosphere. And the feedback that then has on global temperatures is equilibrating somewhere above 450, 550 parts per million, which could lead to warming of two and a half degrees by the end of this century.
We expect to see a two-degree warming with about 450 parts per million CO2 in the atmosphere.
So, we’re on that trajectory, and this is why there’s such an urgency to try to stabilize carbon emissions as quickly as possible within this decade to prevent the most dangerous warming from occurring.
Coursera [00:06:24]: Is there anything we can do to slow the melting of the glaciers or prevent that from happening? Does it all come back to reducing carbon emissions?
Dr. David Hik [00:06:31]: Well, it does. I mean, the bottom line is we don’t know how to reconstruct ice sheets or Arctic sea ice or rain forest or coral reefs–or all of the other life support systems on Earth that are a result of natural biodiversity and ecosystems.
If we wait for things to fully break down, that is rather late to start to try to restore that damage.
So, we really need to look at the commitments that the international community has made and find actions that will reduce those emissions–and try to stay within that safe space, where we won’t see a loss of glaciers, or we won’t see a loss of biodiversity or natural ecosystems.
Coursera [00:07:10]: Can you talk through some of those ideas that you see as a good solution and way to drastically reduce carbon emissions so that we can stop this rise of the climate, which results in the melting of glaciers?
Dr. David Hik [00:07:24] : Well, I think the increase in alternative energy sources–so solar, wind, geothermal–those are being implemented much more rapidly than was initially predicted and could certainly replace a large part of the fossil fuel consumption. Adoption of electric vehicles, more efficient ways of transportation, seem to be being adopted very quickly as well.
Those are important changes. But, conservation of energy will be important as well. Things like moratoriums on developing Arctic oil and gas–or both stopping deforestation and active efforts to plant trees and capture carbon in natural ecosystems, forests, wetlands.
So, several things: some of them are technological, and others are preventing and halting the decline of critical ecosystem services that are actually extremely important in stabilizing the atmosphere of the planet.
Coursera [00:08:16]: And as you’re having these conversations and thinking about these issues often, do you personally hold out hope that these large changes and drastic things that need to happen to slow the rate of climate change will happen in time before that point of no return?
Dr. David Hik [00:08:33]: You know, if you had asked me a couple of years ago, I would have been a little more despondent, but I’m increasingly optimistic that we can bend the emissions curve.
That it’s possible to think about how we emerge from this emergency in a way that benefits humanity, all species, and we can live within the planetary boundaries of the resources that we have on Earth.
Coursera [00:08:55]: Any cities or countries that would be most vulnerable to climate change and specifically would be most affected by things like sea-level changes?
Dr. David Hik [00:09:04]: So, sea-level rise is a function of glaciers melting, and of the thermal expansion of water. As water gets warmer, it occupies a larger volume.
And the oceans are getting warmer. The five warmest years in the ocean in the last 70 years have been 2019, 2018, 2017, 2016, and 2015.
Every year, there’s more heat in the oceans, and this will contribute to an increase in sea level. And so, anywhere on coastlines in every country around the Earth, where people live within a meter of the current high-tide level, will be experiencing a higher frequency of storm surges, an inundation of flooding.
Some areas will be more vulnerable than others. And I think whether it’s industrial ports, like where I live in Vancouver or a place like Miami that’s sitting right on the limits of where the sea level is, or Bangladesh–one of the most densely populated countries in the world lives in a very low lying part of Asia.
Forty percent of its productive land is projected to be lost with sea-level rise by mid-century. And 20 million people that live in the coastal areas of Bangladesh are already affected by salinity and drinking water and contamination of groundwater. And that leads to more health problems, like an increase in diarrhea outbreaks.
So, every part of the world will be affected, and as a result, that just emphasizes to me that this is a global issue that needs a global response.
Coursera [00:10:24]: And as we’re talking about ways that we as humans can adapt, I know we’re already starting to see how the world around us is already adapting plants, animals, et cetera.
Just recently, a study came out that modern plankton look so different than they did historically. They now have thinner shells because of the warming ocean.
Do you see, from your own experience and work in the Yukon, animal species adapting like this, that you’ve seen firsthand?
Dr. David Hik [00:10:54]: Yeah. It’s fascinating. In Yukon, we’ve been able to do things like look at changes in the tree line or the shrub line. So, one of the fairly universal responses to warming that we observe is a shift, an upward shift, in the limit of treeline, the altitudinal limit of treeline and shrub line and Tundra.
So, in a sense, when glaciers melt, that creates new ground that can be occupied by plants and ultimately by animals.
In Yukon, we’ve been able to show that shrubs–little willows and birch shrubs– are advancing upslope and that their density is increasing at about 5 percent per hector per decade.
Now, that may not seem like very much, but it’s also visible to the eye. If I took you there ten years ago, and I took you there this year, one of the very first things you’d notice when you looked up at those hillsides is that the treeline and the shrubs seem more dense, and they’re moving upslope. And we see that in many parts of the world.
And that, of course, means that the species that live at the tops of the mountains, they run out of room. Sooner or later, there’s no more mountain for them to occupy, and there are some good examples now of species that are restricted to high mountains, and mountain tops that are actually disappearing.
Coursera [00:12:03]: So, when we talk through adapting versus going extinct, are those types of plants and animals–where they’re in a more vulnerable ecosystem, or there’s really just not a place for them to relocate and adapt– are those the ones that you think will be more likely to go extinct versus adapt?
Dr. David Hik [00:12:22]: Right? So, people often sort of think the options that species have as to move, adapt, or perish.
So, for a species that’s adapted to a certain temperature, maybe they just have to move around the other side of the boulder and sort of track their preferred climate.
Often, we look at individual species, but species exist within a larger community. And a lot of the work that I’ve been focusing on looks at species interactions so herbivores that eat plants or pollinators that rely on a variety of different species.
There’s other species that have been around for a very long time. My favorite species that I’ve been studying for many years are rock rabbits, or pikas, that live in boulder fields–high, high in the mountains–and they’ve been around for 40 million years. And clearly, they’ve been able to adapt to a variety of situations. They probably have survived warm periods and cold periods and Refugio in mountains, and they’re still there.
But our concern right now is that the rate of change in the climate system– the change in temperature, change in snow change in precipitation–is occurring so quickly that they can’t adapt quickly enough.
And I think that’s the risk that we’re trying to mitigate is how much of a decline in species can we see in a particular place without losing the integrity of that system as a whole?
Coursera [00:13:41]: And do you know, from your research or studies, how long that adaption process happens? The plankton example that we were talking about a bit earlier, that study was over 120 years.
Dr. David Hik [00:13:53]: I mean, evolutionary processes can occur fairly quickly, or they can occur over very long periods of time. But that sort of range of variation is going to be limited to the environmental variation that has been typical of, say, the last 10,000 years or 100,000 years.
We’re moving now into a climate state with warming that is being realized and predicted that is outside of the last 5 million years of Earth history.
So, that’s outside of the entire time that our genus has been on the planet, and for many other species, while they might’ve been around for a long period of time, they’ve slowly–over the last millions or hundreds of thousands of years–adapted to a set of conditions that are typical of what we see now.
And as we move away from now into a warmer future, the rate of adaptation for some species could be very limited. For other species, they might be fine, and other species will simply move. They’ll simply shift their current range into an environment that’s more suitable in a different place.
And I guess the short story is really that we’re still trying to understand and be able to better predict which species will be the winners in those scenarios and which we should be very concerned about and are at greatest risk of extinction.
There’s some other predictors of extinction– habitat loss and fragmentation, susceptibility to invasive species or diseases or parasites. There’s other things besides climate change, but climate change tends to exacerbate all of those other factors.
Coursera [00:15:21]: And when you’re thinking about what animals and plants you’re most concerned about as the planet warms, what are the ones on top of your list?
Dr. David Hik [00:15:29]: So, there are isolated populations, say at lower elevations or on mountain peaks, those are the individuals and the populations that are probably at risk.
There’s no sort of easy way to tell which individuals are going to be at greatest risk.
Small populations, probably at greater risk. There’s a variety of species that I think I’m concerned about, but I think a lot of species will find ways to surprise us. The ones that are at greatest risk are the ones that don’t have any habitat left.
Coursera [00:15:29]: Yeah, and I’m intrigued by the idea that we brought up earlier about how interconnected everything is. Can you talk through exactly what biodiversity is and why it’s important?
Dr. David Hik [00:16:06]: So, biodiversity is a term that we use to generally describe the number of species that live in a particular area, and once we decide what species live in a place, that becomes our inventory of the health of a particular environment.
So, we can do something like create a biodiversity intactness index. People have used this to try to determine if some habitats are at greater risk than others. And we set a limit of 90 percent of the total population that would exist in a pristine version of that habitat that’s sort of free of disturbance and human activity.
If it drops below 90 percent, that’s where we start to set off alarm bells and can take action to prevent crossing a tipping point that could lead to species extinction and cause a collapse of the ecosystem. And the worrying thing is that 50 percent of the Earth’s surface now has dropped below that 90 percent threshold.
So, we have ways of using biodiversity as a measure for how well a particular place on the planet is doing in the face of all of these other disturbances, of which climate changes is one of the most worrying.
Coursera [00:17:15]: And do you have an example to kind of walkthrough, if one plant or animal in an area went extinct, how it could affect the environment around it?
Dr. David Hik [00:17:25]: Well, many of the extinctions we’ve seen have been of large mammals, predators in some cases– species that haven’t gone extinct, but they’ve been lost from certain areas in the mountains.
Mountain caribou in the Rocky Mountains have been in decline for a long period of time, partly from habitat loss or habitat change, partly from predation by wolves and cougars and other predators. And in a number of places, they’re down to sort of the last five or six individuals, so they’re functionally extinct.
I don’t think people would notice a change in the ecosystem if caribou were lost from mountain environments. The predators that are there would probably switch to other prey, to deer or moose or sheep or something like that.
But it’s a sort of intrinsic loss of beautiful things in nature that we will start to notice. We’ll start to eventually notice that there aren’t any rhinoceros or elephants or large cats in parts of Africa. We’ll start to notice that there’s species of fishes that have disappeared completely, from coral reefs as they disappear.
The initial effect on individuals and on the world will be relatively small, but the cumulative effect of that overtime is going to be huge.
All of these changes that we’ve been discussing underpinned our motivation for putting Mountains 101 together.
We tend to think of natural places, and mountains in particular, as very interdisciplinary environments. In my own work, I focused on ecological interactions, but I can’t avoid thinking about the physical parts of those environments, particularly snow and ice, and how species are affected by changes that are occurring in the cryosphere.
And we work in a social environment, and we work with a community that lives in those places and experience firsthand the changes that occur as a result of warming or other disturbances.
So, we talk about the geological origins of mountains, the history of these places. But we also talk about climate, and we talk about the role of glaciers as water towers. And we talk about the natural hazards that occur as gravity moves rocks and mountain and water and snow down to the bottom.
And I do two lessons on mountain biodiversity, focused on plants and the animals, and then we talk about the future of mountains and what some of the consequences of changes will be and what some of the options are for trying to preserve these unique places as well.
So, I always think of a landscape, whether it’s a mountain or a coral reef or a forest in terms of those interconnections. And while we might zoom in on one species, like a pica, those individuals live within a much larger context.
And the more we understand of that larger context–historical, and present and future–I think the more attentive we can be to make sure that we don’t lose them in the longterm.
Coursera [00:20:06]: To keep learning from Dr. David Hik, go to
And as always, and as always, thanks for listening and happy learning.









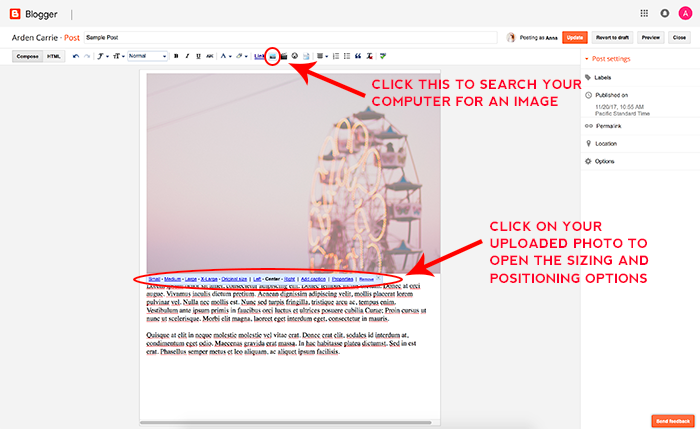


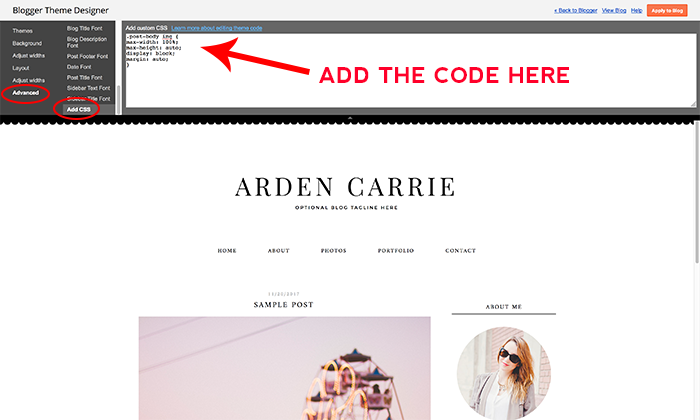
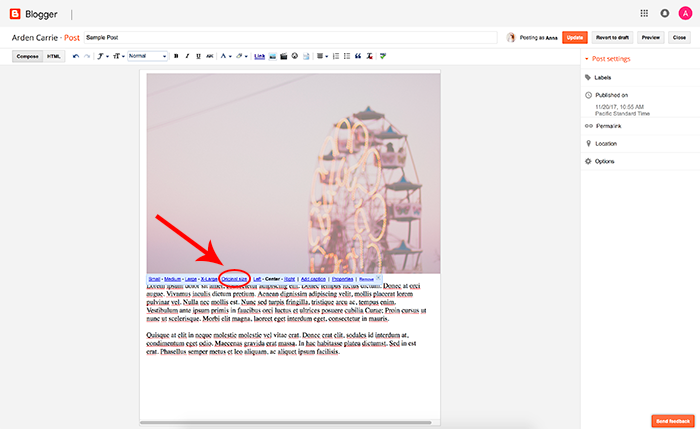

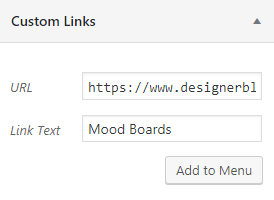
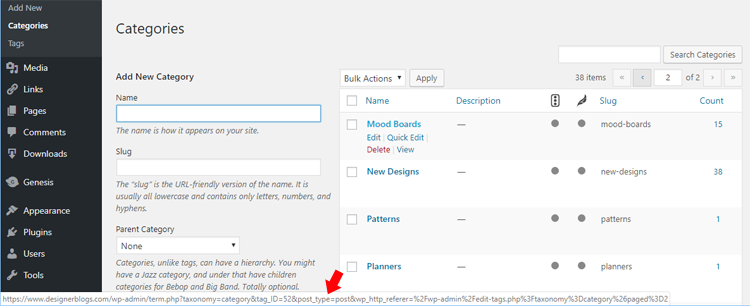
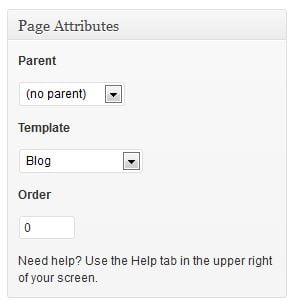
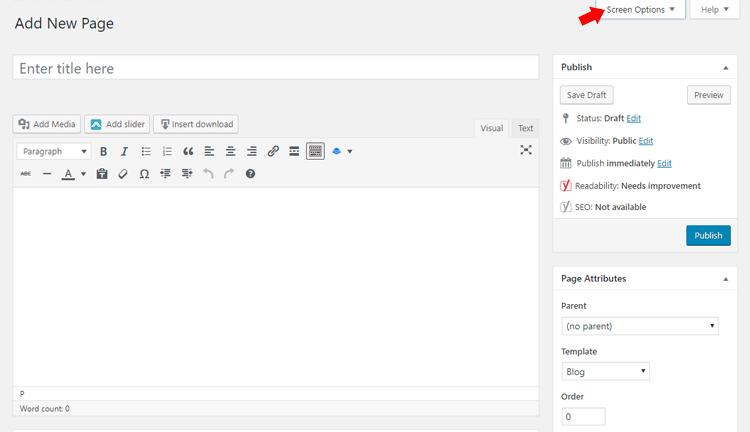
 As your blog content grows, it’s helpful to know different methods for featuring categories on your blog. One of the most popular ways of featuring categories is by adding links to certain categories on your menu bar.
As your blog content grows, it’s helpful to know different methods for featuring categories on your blog. One of the most popular ways of featuring categories is by adding links to certain categories on your menu bar.