
Can you find Peru on a map? What else do you know about this South American nation with about 32.5 million people?
Should Your School Day Start Later?

Find all our Student Opinion questions here.
Do you get enough sleep during the school year? If not, what keeps you from being well rested?
Do you wish your school day started later? In your opinion, what would be the advantages and drawbacks of a later start time?
In “California Tells Schools to Start Later, Giving Teenagers More Sleep,” Christine Hauser and Isabella Kwai write about a new California law that pushes back start times at most public middle and high schools. The law cites research that says attendance and performance will improve if teenagers get more sleep. The article states:
The passage of the law followed years of mounting calls for later school start times from sleep experts who said such a move would optimize learning, reduce tardiness and contribute to overall well-being. The law encourages districts to publish research on their websites about the impact of sleep deprivation on adolescents.
A frequently cited policy statement from the American Academy of Pediatrics, made in 2014, called insufficient sleep for adolescents a “public health issue” and recommended that most schools start no earlier than 8:30 a.m. The American Academy of Sleep Medicine agreed.
In one 2006 poll from the National Sleep Foundation, 45 percent of adolescents in the United States said they slept for an insufficient length of time on school nights, and 19 percent of students said they fell asleep in school at least once a week.
Another study, published in 2017 by the University of Minnesota, which surveyed 9,000 students across five school districts with varying start times, found that those who started school later slept more. Students who had more sleep reported better mental health outcomes and less use of substances like alcohol and cigarettes. Students who slept more also had improved attendance and enrollment rates, and they were less likely to drive while drowsy.
About 90 percent of high schools and 80 percent of middle schools in the nation start before 8:30 a.m., the Centers for Disease Control and Prevention said in 2014.
Students, read the entire article, then tell us:
Do you feel like you get enough sleep?
What would be your ideal time to start the school day? What about to end the school day? Why?
How would changing your school’s start and end times affect activities like sports, clubs and part-time jobs?
Anthony J. Portantino, a Democratic state senator who wrote the bill, calls later start times for schools a “magic bullet” when it comes to education. What are your thoughts on this? Can later start times really improve things like test scores, attendance and graduation rates? Explain.
Students 13 and older are invited to comment. All comments are moderated by the Learning Network staff, but please keep in mind that once your comment is accepted, it will be made public.
Crush your learning goals with Coursera in the car and Amazon Alexa

By Alex Sanchez, Product Management, Mobile Experiences and Emerging Technology at Coursera
No two learner journeys are the same. We’ve seen great diversity across learners in their preferred times, days, and learning session lengths, while some choose to learn via desktop and others embrace mobile. In other words, the flexible options provided by Coursera are being put to good use!
Regardless of your learning habits, consistency is the most important driver of long-term achievement on Coursera. The most successful learners on our platform do not take long breaks between learning sessions; even a three-day break is rare among those with high completion rates.
To help boost the success of all Coursera learners and enable learning wherever you are, we’re excited to announce that Coursera is now available in your car and via our new Amazon Alexa Skill. These new features will propel even more learners to reach their goals through devices they use everyday.
On-the-go learning
Goodbye tangled auxiliary cords! So long Bluetooth pairing problems! Coursera now supports Apple Carplay and, coming soon, Android Auto. Learners can use their in-car infotainment systems to listen to lectures, without assessments or assignments causing distractions behind the wheel. You can also skip or pause a lecture using your car’s media playback system — a much safer option than fumbling with your phone while driving.

Enroll in a course before hitting the road, then learn en route by streaming or playing an already downloaded course. With the average American commute time a little over 26 minutes one-way, this is a particularly practical tool to minimize breaks between learning sessions. On your next car ride, try AI for Everyone from deeplearning.ai, which is one of many courses well suited for learning in the car.
“Hey Alexa, when’s my next assignment due?”
A few weeks ago, the new Coursera skill for Amazon Alexa was announced at the Amazon Day One event. Today we’re excited to share that the skill is available in the Alexa Skills Store. Now you can access assignment due dates and your course progress by simply asking Alexa. In the coming months, you’ll also be able to ask for your course quiz grades.

Voice assistants, like Alexa, are being adopted faster than almost any other technology to date. Recognizing this trend, we saw a chance to increase learner success by leveraging one of the latest, most popular technologies. The skill is available to all learners with a Coursera account and Amazon Alexa-enabled device.
Constant innovation
Being able to learn anywhere, anytime has always been key to the Coursera experience. In 2014, our mobile app made it possible for people around the world to fit learning into their busy lifestyles. We’ve noticed that learners using our mobile app tend to learn in shorter, more frequent bursts than learners exclusively using desktop. The flexibility associated with mobile learning leads to more fruitful habits. Fast forward to today and more than 40% of our learners in the past year have accessed Coursera through mobile.
Each person comes to Coursera with a learning strategy unique to them, so we’re committed to technological innovation to serve these evolving needs. Our team is proud to support all learners with a variety of tools, like Coursera in the car and the Alexa skill, to complement and reinforce learning.
Not a Coursera learner yet? Sign up and enroll in a course for free today.
Word + Quiz: ignominy

ignominy ˈig-nə-ˌmi-nē , -mə-nē and ig-ˈnä-mə-nē noun
: a state of dishonor
_________
The word ignominy has appeared in 16 articles on NYTimes.com in the past year, including on Sept. 2 in “U.S.C. and the Art of Skating on Thin Ice” by Billy Witz:
When Velus Jones returned the opening kickoff 64 yards, it was nullified by a walking-into-a-lamppost-like penalty: The Trojans had two players wearing No. 7 on the field at the same time. By the end of the night, U.S.C. had committed four turnovers and made a number of dubious coaching decisions, but it was spared the ignominy of blowing an 18-point, second-half lead when safety Isaiah Pola-Mao pulled down a brilliant interception in the end zone with less than two minutes left.
Are You a Worrier?

Find all our Student Opinion questions here.
How much of a worrier are you? Do you generally believe things will work out? Or are you constantly thinking about what could go wrong?
In “Always Waiting for the Other Shoe to Drop? Here’s How to Quit Worrying,” Jennifer Taitz writes about how to stop fretting and enjoy your life more:
Ever felt as if the joy of a big win was contaminated with the stress of imagining when the pendulum would swing the other way and something awful would happen to balance it out?
If so, you’re not alone: Often, when driven people care about something and finally experience whatever they’ve been hoping to achieve — whether it’s a new relationship, a health goal, a promotion or something else altogether — they’re unable to entirely savor the good times. They may, in fact, do the exact opposite: endlessly worry about when their peak might plummet.
But taking yourself out of the moment to dread what might happen next won’t prepare you for disaster. Indeed, research has shown that it’s the ability to experience positive emotions that improves our ability to cope with distress. Even better, research from Sonja Lyubomirsky, a psychologist at the University of California, Riverside, finds that experiencing positive emotions doesn’t set you up for disappointment, but increases your likelihood of achieving your work, health and relationship aspirations.
Between chasing goals and then worrying about losing your wins, it’s demoralizing to think that you can’t catch a break. But there are research-based techniques that can help you enjoy the nice life turns while quieting the nagging voices that suggest disappointment is waiting just around the corner.
Here are a few things she suggests:
Notice that worrying will only steal your current joy
One underlying reason people worry is that on some level they assume it helps. Yet we need to accept that we can’t perfectly prepare for potential challenges.
“There are an infinite number of bad things that could possibly happen (although most are unlikely), and there is just no way a person can anticipate them all,” according to Dr. Michel Dugas, a psychology professor at the University of Quebec.
Stop writing off hard work as ‘luck’
Humility is a virtue, but it doesn’t need to come at the expense of creating an enduring sense of faith in yourself. When you play down your accomplishments and abilities with self-deprecating attributions, entirely writing off victories to external factors like chance or timing, you not only perpetuate the belief that something negative is on the horizon, you also miss out on the power of self-efficacy — the mind-set that you have the ability to shape your life. Knowing you can rely on yourself motivates us to strive, and predicts your capacity to manage your emotions effectively and achieve what matters.
Focus on your values, not your goals
It’s easy to fall into the trap of measuring your worth by the various achievements you have reached. Instead, ask yourself:
What virtues do I want to embody?
How do I want to show up right now?
What do I want my life to stand for?
Students, read the entire article, then tell us:
Would you describe yourself as a worrier? When something good happens, are you always waiting for the other shoe to drop, for something bad to happen? Or are you more optimistic about life? Why do you think this way?
Tell us about a time you were especially anxious about something. What were you concerned about and why? How did things turn out? Did worrying help you feel more prepared to face disappointment? Or did it sour the overall experience? If you could do it all again, what, if anything, would you do differently?
What strategies do you have to help yourself stop worrying? Which ones from the article do you think would be most useful in your life? Why?
If you are a worrier, what do you think your life would be like if you didn’t agonize about the future so much?
Students 13 and older are invited to comment. All comments are moderated by the Learning Network staff, but please keep in mind that once your comment is accepted, it will be made public.
Lesson of the Day: ‘From Chile to Lebanon, Protests Flare Over Wallet Issues’

Find all our Lessons of the Day here.
Lesson Overview
Featured Article: “From Chile to Lebanon, Protests Flare Over Wallet Issues”
Pocketbook items have become the catalysts for popular fury across the globe in recent weeks. In this lesson, students will explore why people protest, examine the factors and causes of this recent wave of protest, and finally choose one protest movement to research further.
Warm Up
Have you ever participated in a protest, march or demonstration? If yes, what motivated you to participate? If not, what might convince you to join one?
Before reading, consider protest movements from the past — such as the civil rights movement — or examples from more recent history.
Then, make a list of reasons people protest.
Next, find a partner and share and discuss your lists.
Finally, reflect together: Which reasons would most likely lead you to protest? Do you think protests can bring about meaningful change?
Questions for Writing and Discussion
Read the article, then answer the following questions. As you read the article, add to or amend your list from the warm-up:
1. What have been the catalysts in the recent wave of “unexpected protests” in Chile, India, Lebanon and Saudi Arabia? Which do you find most interesting or surprising? How do these reasons for protesting compare to your list from the warm-up activity?
2. Why were many of the leaders surprised by the outbreak of protests in their country? In particular, why did President Sebastián Piñera of Chile think he was immune to this type of public dissent?
3. While many of the protests have occurred on different continents across the globe, what “patterns” have experts recognized? What roles do economic inequality and changing youth demographics play in these movements?
4. Why do some like Michael Ignatieff, president of Central European University, warn against finding a common theme or category to these protests?
5. The article notes, “But as protest movements grow, their success rates are plunging.” Explain this paradox.
6. What factors contribute to the success or failure of a protest, according to the article? Why do many social media fueled protests “rise faster, but collapse just as quickly”?
7. What is your reaction to the article? Which quotation or image stands out most? Explain why. Does the article change any of your ideas about the value and role of protests?
Going Further
Choose one protest movement discussed in the article to research further. Use the following questions as a guide:
What events or factors led to the protests?
Who is participating in the protests? Are there any leaders or organizations directing them?
What are the goals of the protests? What strategies and tactics are (or were) being used to achieve them?
If the protests have ended, in what ways were they successful? If the protests are still continuing, what predictions do you have about their ultimate success or failure?
Then, write about or discuss with your classmates: What additional insights did you gain about why people protest? If you were in the country you chose to research, would you consider joining the protests? Why or why not? Over all, do you believe protests are an effective way to bring about meaningful change in society? Explain why you think the way you do.
Coursera for Business Releases Skills Development Dashboards to Measure Learning Outcomes

By Shwetabh Mittal, Director of Enterprise Product

Companies are racing to acquire skills that are fast in motion — 42 percent of the core job skills required today are predicted to change substantially by 2022. Equipping employees with critical skills is now a top-level priority, with the availability of key skills viewed as the top three business threat for CEOs globally. With so much resting on the ability to transform talent, measuring skills development is paramount. L&D leaders are expected to quantify learning outcomes to ensure that their employees are gaining the skills needed to compete and prove overall ROI.
Today, we’re excited to release Skills Development Dashboards, featuring skills-based metrics that enable our customers to report on their learning programs in more detail than ever before. The new dashboards are an expansion of the Skills Benchmarking tool released last year and provide an in-depth snapshot of the skills an organization is learning on Coursera.
These are some of the highlights:
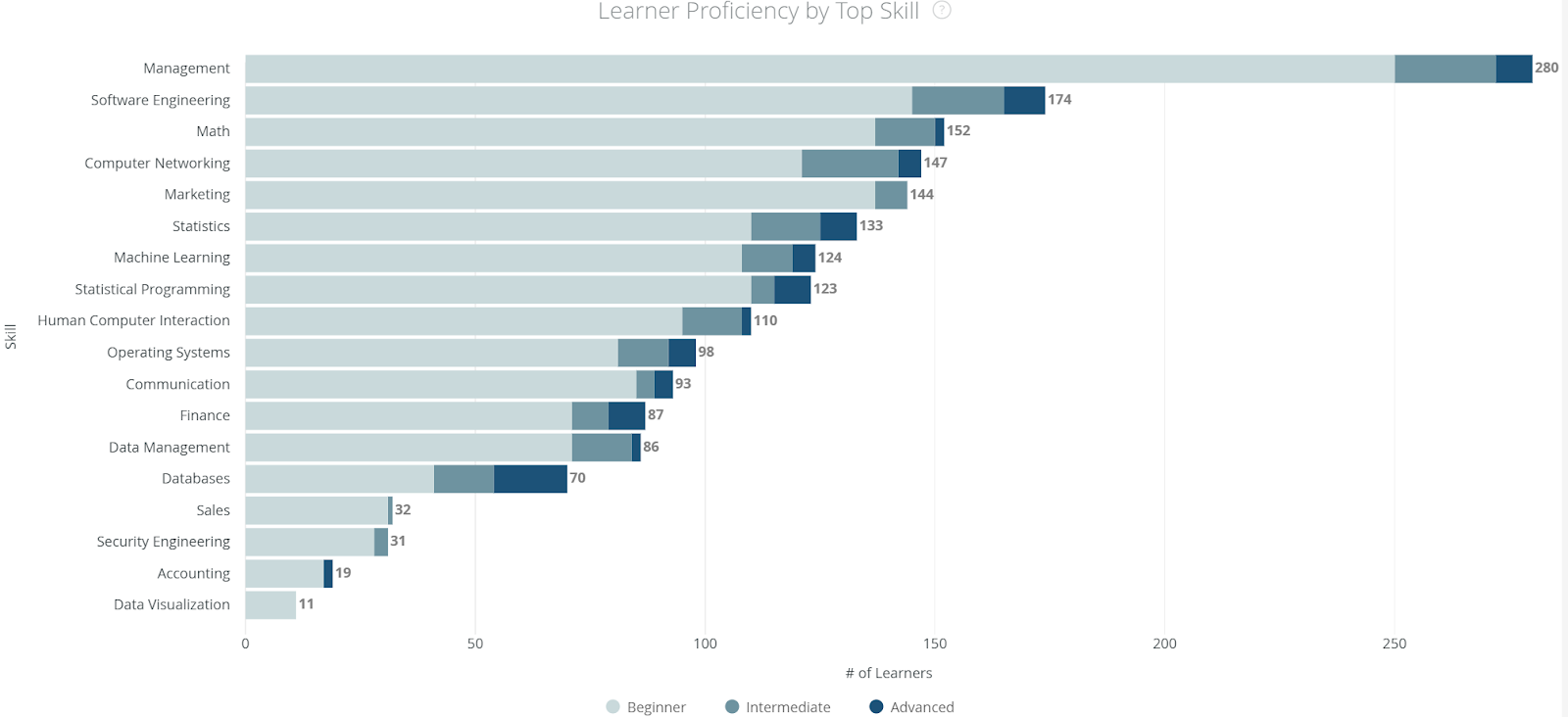
Learner Proficiency by Top Skill: Learner proficiency by skill, shown below, provides an overview of how many learners in an organization are at what level of skill mastery (Beginner, Intermediate, or Advanced) for the most popular skills learned at the company. It’s a powerful ROI snapshot to report out to stakeholders, and it can also be used to better understand what skills or proficiency bands to focus on in training.
Average Hours to Mastery: This dashboard displays the median number of hours it takes for learners in an organization to get to the next level of skill mastery. With this, learning leaders can understand exactly how much time investment is required for developing a certain skill to a certain level of proficiency. It also enables them to identify skills that are either a quick win or too time-intensive to be ROI-positive for an organization.
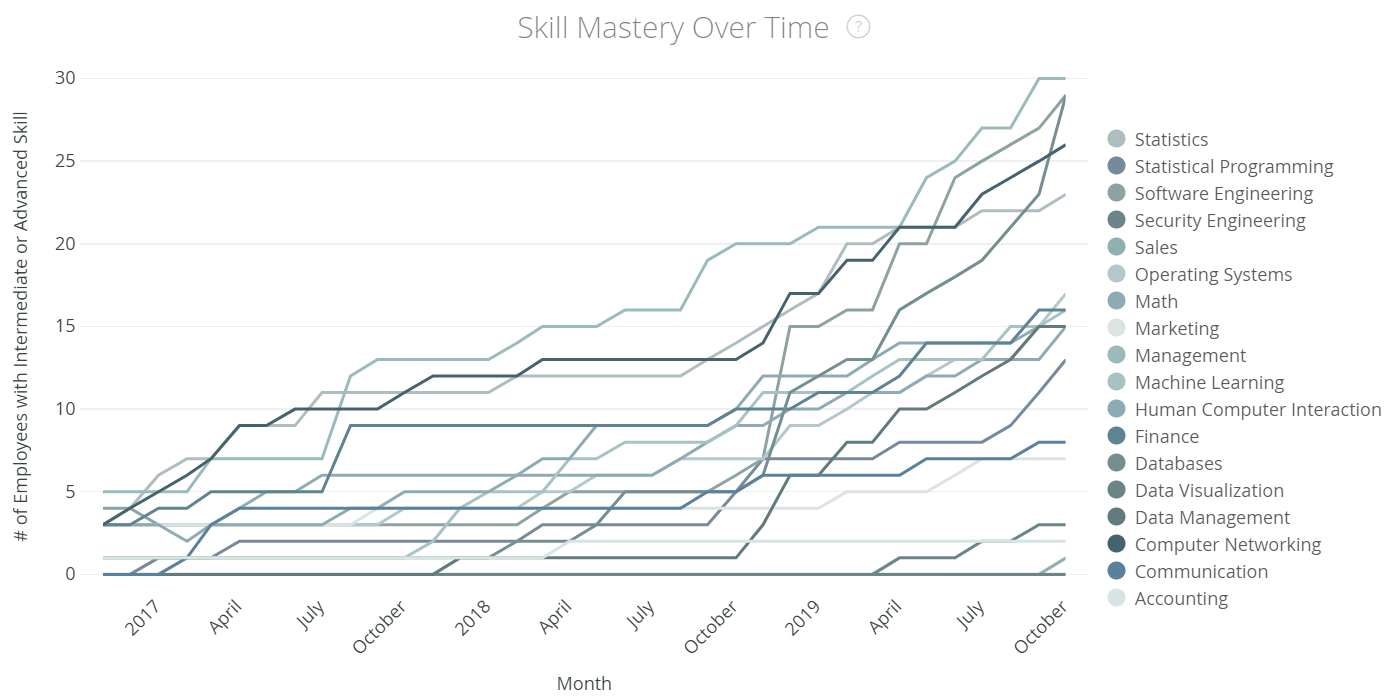
Skill Mastery Over Time: This dashboard, shown below, shows how many learners have reached the Intermediate and Advanced levels of mastery over time, by skill. Using this, learning leaders can identify whether their learners are tracking towards mastering the skills they need, and ultimately whether their learning engagement strategy is effective.
Most Relevant Courses per Skill Level: This dashboard identifies the most relevant courses an organization is taking to learn a skill, making it easy to identify which content is relevant and popular with learners at intermediate and advanced levels. It’s also helpful for recommending content to learners that are just embarking on their learning program without having to sift through Coursera’s robust catalog of 3,600 courses.
The dashboards are built atop our Skills Graph, which analyzes the performance of millions of learners on graded assessments on the Coursera platform. By layering the Skills Graph with a variant of the Elo chess algorithm, we can estimate learner skill proficiency by viewing learners taking assessments as competitors in a match. When a learner passes or fails an assessment, their skill proficiency estimate increases or decreases, respectively. From there, we can measure learner skill proficiency over time, adjusting for the difficulty of courses taken.
Companies of all sizes and across industries will benefit from these new dashboards. Over 10 Coursera for Business customers have already participated in the pilot and are excited to apply the insights from the Skills Development dashboards to their own learning organizations.
Want to learn more about how Skills Development Dashboards can inform your L&D strategy? Reach out to us today.

Coursera for Business provides a world-class learning platform for companies that need to upskill, reskill, and deepskill their talent. With topics ranging from digital transformation and data science to software development and leadership, over 2,000 companies trust the Coursera for Business enterprise platform to transform their talent.
What’s Going On in This Picture? | Oct. 28, 2019

Students
1. After looking closely at the image above (or at the full-size image), think about these three questions:
2. Next, join the conversation by clicking on the comment button and posting in the box that opens on the right. (Students 13 and older are invited to comment, although teachers of younger students are welcome to post what their students have to say.)
3. After you have posted, try reading back to see what others have said, then respond to someone else by posting another comment. Use the “Reply” button or the @ symbol to address that student directly.
Each Monday, our collaborator, Visual Thinking Strategies, will facilitate a discussion from 9 a.m. to 2 p.m. Eastern time by paraphrasing comments and linking to responses to help students’ understanding go deeper. You might use their responses as models for your own.
4. On Thursday afternoons, we will reveal at the bottom of this post more information about the photo. How does reading the caption and learning its back story help you see the image differently?
Who Do You Turn To in a Crisis?

Find all our Student Opinion questions here.
Do you find it easier to share your feelings with teenagers than with adults? What’s the best advice you’ve been given by someone your own age?
In “It Takes a Teenager to Help a Teenager in Crisis,” Catherine Cheney writes about a nonprofit crisis hotline where adolescents receive counsel from their peers. She writes:
After losing his best friend to suicide, Taylor Harrison, then 18, was looking for ways to honor the memory of his friend, deal with his own grief, and help others going through a hard time. He decided to volunteer at Lines for Life, a nonprofit crisis-line organization in Portland, Oregon.
Just a few months into his time there, Mr. Harrison took a call from a teenager who was thinking about walking in front of the next train. “It was really brave of you to reach out,” he told the caller. The teenager eventually decided the library was the safest place for him to go, and Mr. Harrison stayed on the phone with him while he took the bus there.
Mr. Harrison, who is now 23, later joined the staff at YouthLine, a service that Lines for Life offers for those aged 11 to 21. He said he dreams of discovering what that caller went on to accomplish.
Youth suicide is climbing faster than suicide by any other age group, perhaps because of social media, which can cause rising anxiety and depression among teenagers. While peer support has proved effective for adults with mental health challenges, scientific evaluations of teenagers helping one another are difficult to find — even though some limited studies show that teenagers experiencing the stress of adolescence cope better emotionally when they are with their friends than with their parents. YouthLine is one of six youth lines across the country that have demonstrated how teenagers can relate to their peers over the internet or the phone in a way that adults are sometimes unable to do.
These peer-run crisis lines are coming together to bring more young voices to crisis intervention. But to spread this service nationwide, they will have to convince the skeptics that teenagers can do this work.
The Op-Ed continues:
But not everyone thinks teenagers can or should take calls from people in crisis.
Crisis Text Line, a nonprofit that provides crisis intervention by text, decided to steer clear of volunteers under the age of 18 for a few reasons, according to Dr. Shairi Turner, who was the first chief medical officer at the organization. She said she is concerned that conversations with people in crisis “run the risk of vicarious trauma” for teenage volunteers.
Wendy Farmer, the chief executive of Behavioral Health Link in Atlanta, also had reservations about the model, until she visited Lines for Life last August. “The clinician in me said, ‘Wow, it’s a great idea, but I don’t know if we want to expose young people to what happens on a crisis line,’” she said.
Initially, Ms. Farmer traveled to Portland to learn how the adults who run her lines could better relate to teenagers or preteens. But she said she was “really blown away” by the young people she met. Ms. Farmer went through the YouthLine orientation, spent a night on shift and conducted a focus group with some of the volunteers. She said she was struck by how smart the students were — indeed, she said, the 15-year-old she was paired with for an exercise in reflective listening did a better job than she did.
Students, read the entire article, then tell us:
Are adults a good source for advice because of their life experience and knowledge? Or do you see them as out of touch, patronizing or judgmental? Do you relate better to your peers, or do you see them as naïve and immature?
Would you ever want to work as a teenage counselor? Would you worry about experiencing “vicarious trauma”? Or that you might be ill equipped to intervene if someone came to you with serious issues involving self-harm, for example, or abuse? How important is it for people in crisis to have someone just to listen to them?
Students 13 and older are invited to comment. All comments are moderated by the Learning Network staff, but please keep in mind that once your comment is accepted, it will be made public.
The Guggenheim

Frank Lloyd Wright’s Solomon R. Guggenheim Museum in New York City turns 60 this month. The Times architecture critic Michael Kimmelman writes that even after all these years, it is “still a shock on Fifth Avenue. The architecture declines to fade into the background or get old … Happy birthday to one of modern architecture’s transcendent achievements!”
Has a building ever inspired strong emotion in you — whether because you are in awe of it, repelled by it, confused by it, or something else? Where is this building and why do you think you have such a strong reaction to it?
Tell us in the comments, then read the related article to see more photos of the Guggenheim and learn about how it was built.
Find many more ways to use our Picture Prompt feature in this lesson plan. You can find all our Picture Prompts in this column.
